


Iterative Self-Correction
Ethics is just one place it could work

On Monday I congratulated all my Canadian readers on Victoria Day, and mentioned Memorial Day would be the following week. I was wrong on both counts. Victoria Day is next Monday and Memorial Day follows the week after that. The rest of the analysis holds.
Yesterday’s subscriber-only post was about new generative AI interfaces beyond “chat”. You can subscribe here to read it. In the meantime, today’s post:
This Week’s Sponsor

Get Your SOC 2 in 2 Weeks
Need a SOC 2 ASAP? Vanta, the leader in automated compliance, is running a one-of-a-kind program for select companies where we'll work closely with you to get a SOC 2 Type I in JUST TWO WEEKS. This can help you close more deals, hit revenue targets, and lay a foundation of security best practices.
AIs like GPT-4 go through two rounds of training. First, they train on giant text corpuses in order to work at all. Second, they go through a process called “reinforcement learning through human feedback” (RLHF) which trains them to be “nice”. RLHF is why they (usually) won’t make up fake answers to your questions, tell you how to make a bomb, or rank all human races from best to worst.
RLHF is hard. The usual method is to make human crowdworkers rate thousands of AI responses as good or bad, then train the AI towards the good answers and away from the bad answers. But having thousands of crowdworkers rate thousands of answers is expensive and time-consuming. And it puts the AI’s ethics in the hands of random crowdworkers. Companies train these crowdworkers in what responses they want, but they’re limited by the crowdworkers’ ability to follow their rules.
In their new preprint Constitutional AI: Harmlessness From AI Feedback, a team at Anthropic (a big AI company) announces a surprising update to this process: what if the AI gives feedback to itself?
The idea is:
Ask the AI to write something
Show the AI what it wrote and ask it to “re-write to be more _____”
Repeat until there is a large amount of revisions
Train the AI on the revised content (and against the original versions)
This is not unlike how you can get the AI to be better at anything:
Coding:
Ask the AI to write code
Run the code. Get error messages (or anything else that is not what you intended)
Give the error messages back to the AI and ask it to fix the code
The AI fixes the code and it works
Writing:
Ask the AI to write something
Explain to the AI what it got wrong and ask it to try again (or sometimes just, “That seems like a 7/10. Please re-write it as a 10/10”)
AI writes something better and more matching what you were looking for
Anecdotally this iterative process works. When I explain it to people they often ask , “why can’t the AI get it right the first time? It clearly has the knowledge, because it gives the right answer the second time!”
What Anthropic is doing is exactly that! It takes AI v1 and asks it to try a second time, and then trains AI v2 to answer the first time the way AI v1 answered the second time. Anthropic is doing this primarily in the ethics realm, but as far as I understand there is no reason this technique could not be used to just “improve quality” along some other dimension.
And QUANTITATIVELY the method works. Here is a visual of the performance improvement:
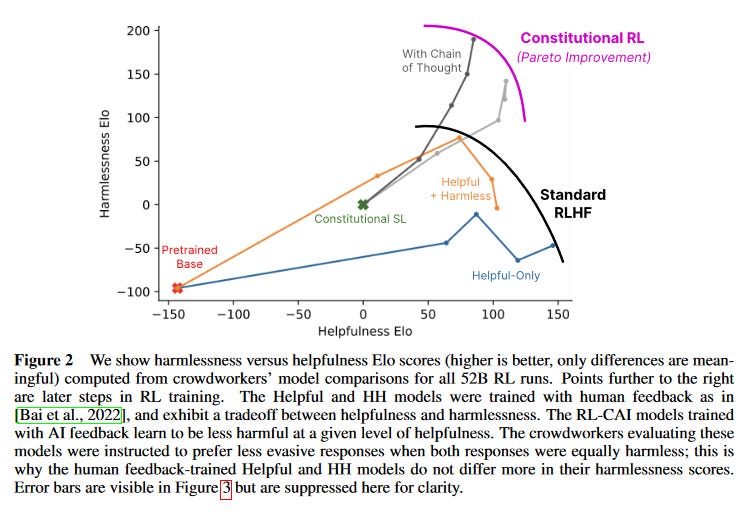
The x-axis shows how “helpful” the AI’s answers are. The y-axis is how "safe” the answers are. Ideally (at least according to the platforms training the models), the goal is a model that is both perfectly helpful and perfectly safe. In practice researchers have found a trade off, where at some level of optimization a more helpful AI is less safe, and a safe AI is a little less helpful. What is cool about the new AI-self-improvement method is it shifts that “pareto frontier” out to the upper left. The most-optimized to date “constitutional model” is still not as helpful as the best “helpful only” model, but it is well past the previous “theoretical trade-off limit”.
What can you do with this?
I share this both because it is interesting, but also because it is quantitative evidence that iterative effort with AI language models DOES lead dividends. You should not provide a single prompt and then assume that is the best output. Unless you don’t care about quality, the “right” answer is usually to provide feedback after any given response and ask for something better.
Not unlike how one might manage a junior employee.
Keep it simple,
Edward